Toda computadora debe realizar operaciones aritméticas. La notación en el lenguaje ensamblador MIPS
add a, b, c
Instruye a la computadora a sumar las dos variables b y c y colocar la suma en a.
Esta notación es rígida, en el sentido que cada instrucción aritmética de MIPS realiza una sola operación y debe tener tres variables (“variable” en un sentido vago, mas adelante se analizarán los operandos en MIPS). Si se quieren sumar las variables b, c, d y e en la variable a, será necesaria la secuencia:
add a, b, c # La suma de b y c es puesta en a
add a, a, d # La suma de b, c y d es puesta en a
add a, a, e # La suma de b, c, d y e es puesta en a
Toma tres instrucciones sumar cuatro variables.
Como en todos los ensambladores, cada línea contiene a lo mas una instrucción, y en este caso, los comentarios inician con el símbolo # y terminan al final del renglón.
El número natural de operandos para una operación aritmética como la suma es tres, los dos operandos a sumar y el operando donde se colocará el resultado. Por lo que es adecuado que las instrucciones aritméticas cuentes con tres operandos: no más o menos; de acuerdo con la filosofía de mantener un hardware simple, es evidente que el hardware para un número variable de operandos es mas complicado que el hardware para un número fijo. Esta situación ilustra el primero de cuatro principios para el diseño de hardware:
Principio de diseño 1: La simplicidad favorece la regularidad.
En los ejemplos siguientes se muestra la relación que existe entre un lenguaje de alto nivel y el código MIPS.
Ejemplo: Compilando dos asignaciones a código MIPS
Este segmento de un programa en C contiene cinco variables a, b, c, d y e:
a = b + c;
d = a – e;
La traslación desde C al ensamblador MIPS la realiza el compilador correspondiente, mostrar el código MIPS que produciría para estas asignaciones.
Respuesta:
Una instrucción MIPS opera con dos operandos fuentes y pone el resultado en un operando destino. Para dos asignaciones simples, solo se requiere de dos instrucciones:
add a, b, c
sub d, a, e
Ejemplo: Compilando una asignación mas compleja
Para la siguiente asignación en C:
f = (g + h) – (i + j);
¿Qué produciría el compilador?
Respuesta:
El compilador separa la asignación y utiliza variables temporales, de manera que el resultado es:
add t0, g, h # La variable temporal t0 contiene g + h
add t1, i, j # La variable temporal t1 contiene i + j
sub f, t0, t1 # f obtiene t0 – t1, que es (g + h) – (i + j)
Hasta el momento no se ha puesto atención a los símbolos involucrados en el código MIPS, sin embargo, a diferencia de los lenguajes de alto nivel, los operandos de las instrucciones no pueden ser cualquier variable; mas bien quedan limitados por un número especial de localidades llamadas registros. Los registros son los ladrillos en la construcción de una computadora, se definen durante el diseño del hardware y quedarán visibles al programador cuando la computadora este completada.
Una principal diferencia entre las variables de un lenguaje de programación y los registros, es el limitado número de registros. MIPS tiene 32 registros, por lo que para una instrucción aritmética se puede elegir entre 32 registros de 32 bits para los tres operandos.
La razón del límite en 32 registros se explica con el segundo principio del diseño de hardware.
Principio de diseño 2: Si es mas pequeño es más rápido.
Un número muy grande de registros automáticamente incrementa el tiempo del ciclo de reloj, simplemente por que las señales eléctricas requieren de mas tiempo cuando necesitan viajar mas lejos.
Directivas tales como “Si es mas pequeño es más rápido” no son absolutas; 31 registros no pueden ser mas rápidos que 32. Los diseñadores de hardware debe tomar muy en cuenta este principio y balancear entre el deseo anormal de los programadores por contar con un número grande de registros con el deseo de los diseñadores de mantener un ciclo de reloj rápido.
Aunque se podrían simplemente considerar los números del 0 al 31 para nombrar a los registros, para no confundirlos con valores constantes, por conveniencia se les antepone el símbolo de pesos ($), de manera que los registros son $0, $1, . . ., $31. Además, para desarrollar un código simple, a los registros que correspondan directamente con los nombres de las variables en alto nivel, les llamaremos $s0, $s1, . . .; y a los registros temporales les llamaremos $t1, $t2, $t3, . . . Esto sólo por convención, en la tabla 3.2.1 se muestran las convenciones utilizadas. (vease tambien la figura 3.1.2 para mayor detalle)
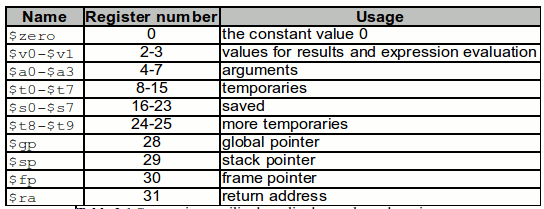
Tabla 3.1.2 Convenciones utilizadas aplicadas en el uso de registros en MIPS
Puede notarse que el registro $0 siempre contendrá el valor 0, este convención es bastante útil cuando se realizan comparaciones con cero o brincos condicionales.
Ejemplo: Uso de registros.
En este ejemplo se repite el ejemplo anterior, pero ahora se utilizarán los nombres de los registros en el código ensamblador.
f = (g + h) – (i + j);
¿Qué produciría el compilador?
Respuesta:
Supongamos que las variables f, g, h, i y j se asocian con los registros $s0, $s1, $s2, $s3 y $s4, respectivamente.
add $t0, $s1, $s2 # El registro $t0 contiene $s1+ $s2
add $t1, $s3, $s4 # El registro $t1 contiene $s3+ $s4
sub $s0, $t0, $t1 # f obtiene $t0 – $t1, que es (g + h) – (i + j)
Los lenguajes de programación usan variables simples que se asocian directamente con registros; sin embargo también utilizan estructuras de datos un poco mas complejas como es los arreglos; y no es posible que un arreglo pueda ser contenido en los registros del procesador.
Recordando los cinco elementos clásicos de la computadora (figura 3.2.1), notamos que debido al número limitado de registros, el lugar mas adecuado para las estructuras es la memoria.
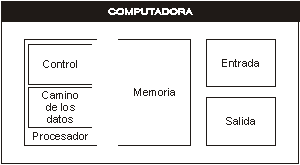
Figura 3.2.1 Componentes de una computadora
Sin embargo acabamos de mencionar que las instrucciones aritméticas solo se realizan con los operandos en registros, por lo que la arquitectura MIPS debe incluir algunas instrucciones que permitan la transferencia de datos de memoria a registros y viceversa. A la memoria la podemos considerar como un arreglo unidimensional, grande, con las direcciones actuando como índices en el arreglo, iniciando en la 0. Por ejemplo, en la figura 3.2.2, la dirección del tercer dato en memoria es 2 y su valor es Memoria[2] = 10.
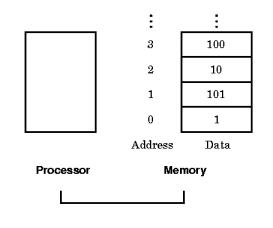
Figura 3.2.2. Direcciones de Memoria y su contenido en algunas localidades
La instrucción que mueve datos desde la memoria a un registro se le conoce como carga, y su formato es:
lw $s0, 100 ( $s1 ) que significa $s0 = Memoria[$s1+ 100 ]
lw es el nombre de la instrucción (load word) , el primer registro que aparece en la instrucción es el que será cargado ($s0, en este caso), luego se incluye una constante (100, en este caso)a la cual le llamaremos desplazamiento (offset) y finalmente entre paréntesis encontramos otro registro ($s1, en este caso), a este registro le llamaremos registro base. La dirección de la palabra a cargar se forma sumando el valor del registro base con el desplazamiento.
Ejemplo: Carga de memoria.
Para la siguiente asignación en C :
g = h + A[8];
¿Qué produciría el compilador? Suponiendo que el comienzo del arreglo A se encuentra en el registro $s0, y que las variables g y h se asocian con los registros: $s1 y $s2, respectivamente.
Respuesta:
Primero se debe accesar a la memoria para la lectura del dato:
lw $t0, 8( $s0) # El registro $t0 contiene A[8]
Ahora ya es posible realizar la suma:
add $s1, $s2, $t0 # g = h + A[8]
Los compiladores son los que se encargan de asociar las estructuras de datos con la memoria. Por lo que el compilador debe poder colocar la dirección adecuada en las instrucciones de transferencias.
Puesto que 8 bits (1-byte) son útiles en muchos programas, la mayoría de computadoras conservan el direccionamiento por bytes individuales. Por lo que el direccionamiento por palabras se refiere a la lectura de un conjunto de 4 bytes. Esto significa que las direcciones secuenciales de palabras deben diferir en 4. En la figura 3.2.2 se mostraron a los datos con direcciones continuas, sin embargo, puesto que se están considerando palabras (de 32 bits), la distribución correcta de los datos sería la que se muestra en la figura 3.2.3.
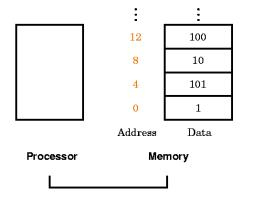
Figura 3.2.3. Direccionamiento por palabras
Debido a que las memorias organizan a los datos por bytes, cuando se manejan arreglos de palabras se afecta a los índices de los mismos, entonces el compilador debe calcular adecuadamente la dirección del dato que será transferido. En el último ejemplo, para que se haga la lectura correcta del elemento 8 del arreglo A, el desplazamiento debe multiplicarse por 4, de manera que a $s0 se le sume 32 (8x4), así se seleccionará al dato A[8] y no a A[8/4].
La instrucción complementaria a la carga se llama almacenamiento (store), para transferir un dato desde un registro a la memoria. Su formato es similar al de las instrucciones de carga:
sw $s0, 100 ( $s1 ) que significa Memoria[$s1+ 100 ]=$s0
sw es el nombre de la instrucción (store word).
Ejemplo: Carga y Almacenamiento.
Para la siguiente asignación en C :
A[12] = h + A[8];
¿Qué produciría el compilador? Suponiendo que el comienzo del arreglo A se encuentra en el registro $s0, y que la variable h se asocia con el registro $s1:
Respuesta:
Primero se debe accesar a la memoria para la carga del dato:
lw $t0, 32( $s0) # El registro $t0 contiene A[8]
Ahora ya es posible realizar la suma:
add $t0, $s1, $t0 # El registro $t0 contiene h + A[8]
Por último se realiza el almacenamiento:
sw $t0, 48( $s0) # A[12]= h + A[8]
Se puede observar que los índices del arreglo (8 y 12) se multiplicaron por 4 para obtener las direcciones adecuadas de los datos en memoria.
Ejemplo: Usando una variable como índice de un arreglo.
La siguiente asignación utiliza a la variable i como índice del arreglo A :
g = h + A[i];
¿Qué produciría el compilador? Suponiendo que el comienzo del arreglo A se encuentra en el registro $s0, y que las variables g, h e i se asocian con los registros: $s1, $s2 y $s3, respectivamente.
Respuesta:
Antes de accesar a la memoria se debe obtener la dirección adecuada del dato a leer, puesto que solo hemos considerado instrucciones de suma, primero obtendremos i x 4 realizando i + i = 2i, y luego 2i + 2i = 4i:
add $t0, $s3, $s3 # $t0 = i + i = 2i
add $t0, $t0, $t0 # $t0 = 2i + 2i = 4i
La carga se hace con la instrucción:
lw $t1, 0( $t0) # $t1 = contiene A[i]
Finalmente se realiza la suma:
add $s1, $s2, $t1 # g = h + A[i]
Muchos programas tienen mas variables que registros en el procesador. En consecuencia, el compilador intenta mantener a las variables mas usadas en registros y el resto en memoria, usando cargas y almacenamientos para mover variables entre registros y memoria. El proceso de poner a las variables menos usadas (o aquellas que se usaran posteriormente) en memoria se conoce como derramamiento de registros (spilling registers).
El principio de hardware que relaciona el tamaño con la velocidad sugiere que la memoria debe ser mas lenta que los registros porque el tamaño del conjunto de registros es menor que el de la memoria. El acceso a los datos es mas rápido si los datos están en registros.
Y los datos son más útiles cuando están en registros por que una instrucción aritmética se aplica sobre dos registros, mientras que los accesos a memoria solo manipulan un dato.
En conclusión, los datos en los registros en MIPS toman un menor tiempo y tienen una productividad mas alta que los datos en la memoria. Para aumentar el rendimiento, los compiladores MIPS deben usar los registros eficientemente.